
Cloudflare lança ferramenta que permite cobrar rastreadores de IA pelo acesso a sites
A Cloudflare apresentou o “Pay per Crawl”, um novo marketplace que oferece aos editores maior controlo sobre a actividade de bots de inteligência artificial e a possibilidade de gerar receita a partir do acesso desses crawlers aos seus conteúdos.
Inteligência Artificial
20, Novembro de 2025
O serviço, denominado Pay per Crawl, permite que criadores de conteúdo definam se desejam permitir, bloquear ou cobrar pelo acesso de rastreadores automatizados de IA às suas páginas, estabelecendo um modelo de monetização até agora inexistente no ecossistema digital.
Lançado em beta privado, no início do primeiro semestre deste ano, o Pay per Crawl integra-se à infraestrutura da Web já existente e utiliza códigos de estado HTTP e mecanismos de autenticação para identificar crawlers e aplicar cobranças conforme as regras definidas pelos proprietários de conteúdo. A Cloudflare actua como intermediária no processamento dos pagamentos, agregando os acessos pagos e distribuindo os ganhos aos editores.
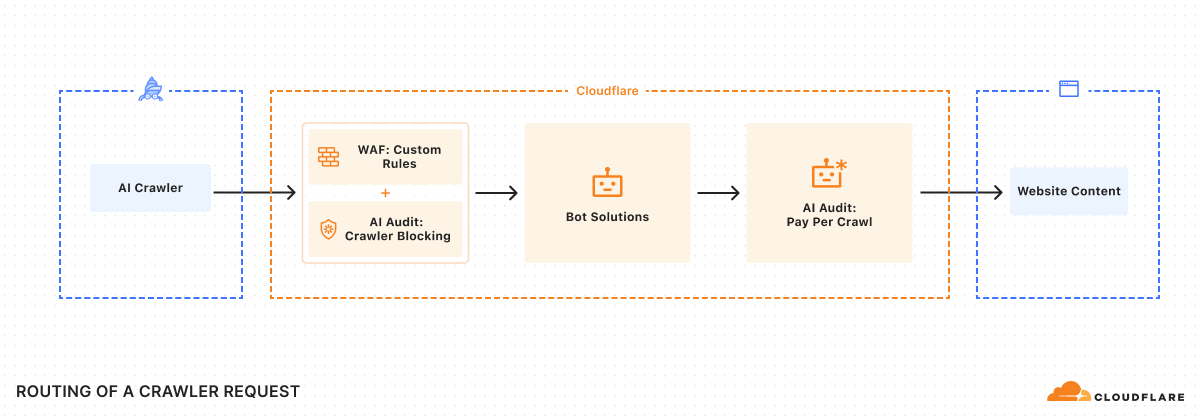
Segundo a empresa, a ferramenta surge como resposta à crescente preocupação de criadores de conteúdo, editoras e plataformas digitais, que se vêem hoje entre duas opções extremas: permitir que crawlers de IA acedam livremente ao seu conteúdo ou bloquear totalmente esses acessos, limitando a visibilidade online. O novo marketplace introduz uma alternativa intermédia, permitindo o acesso mediante pagamento.
A Cloudflare explica que cada pedido feito por um rastreador de IA poderá resultar em três respostas, conforme a escolha do editor: acesso gratuito, cobrança ou bloqueio total. Mesmo que um crawler não tenha ainda relação de facturação estabelecida com a Cloudflare, o sistema pode tratá-lo como “cobravel”, funcionando como uma forma ampliada de bloqueio que indica a possibilidade de negociação futura.
Para evitar que agentes maliciosos se façam passar por crawlers legítimos, o sistema recorre a autenticação avançada baseada em pares de chaves e assinaturas de mensagens HTTP, garantindo que apenas rastreadores registados possam efectuar pedidos pagos ou gratuitos.
A solução opera com dois fluxos de acesso: um fluxo reactivo, no qual o crawler descobre o preço apenas após tentar aceder ao conteúdo, recebendo um código HTTP 402 – Payment Required; e um fluxo proactivo, no qual o rastreador declara antecipadamente o preço máximo que está disposto a pagar. Em ambos os casos, o acesso só é concedido se o valor corresponder às condições definidas pelo editor.
A Cloudflare afirma que o objectivo é dar aos criadores de conteúdo maior controlo num momento de rápida transformação digital.
O crescimento da recolha automatizada de dados para treino de modelos de IA tem pressionado editores, sobretudo do sector noticioso, que enfrentam queda no tráfego proveniente de motores de busca e concorrência crescente de sistemas de IA generativa. Enquanto grandes organizações, como o New York Times, já firmaram acordos de licenciamento com empresas tecnológicas, muitos editores de menor escala continuam sem alternativas viáveis para monetizar o uso dos seus conteúdos.
A empresa acredita que o Pay per Crawl poderá evoluir para modelos mais sofisticados, incluindo preços diferenciados por tipo de conteúdo, licenças específicas para treino ou inferência de IA, e mecanismos inteiramente programáticos que permitam a agentes inteligentes negociar o acesso a recursos digitais de forma automática.
O Pay per Crawl permanece em fase de testes privados e a Cloudflare está a recolher inscrições tanto de criadores de conteúdo interessados em cobrar pelo acesso quanto de operadores de crawlers que pretendam integrar o sistema.
Publicações mais recentes
Placeholder text for title
Placeholder text
Placeholder text
Placeholder text for title
Placeholder text
Placeholder text
Placeholder text for title
Placeholder text
Placeholder text
Placeholder text for title
Placeholder text
Placeholder text
Inscreva-se e faça parte da nossa comunidade de entusiastas conectados e antenados.